SLMs on Edge - FPGA Accelerator for Qwen3 SLM Inference
1st Runners-Up at DVCon India 2025 - Custom accelerator for full Qwen3 inference pipeline on RISC-V SoC
Project Gallery

About This Project
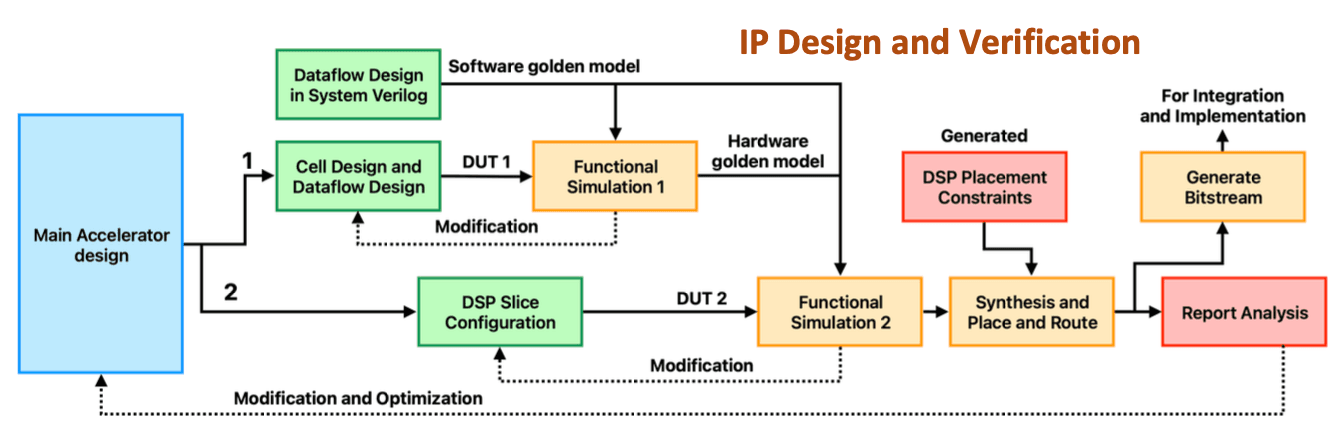
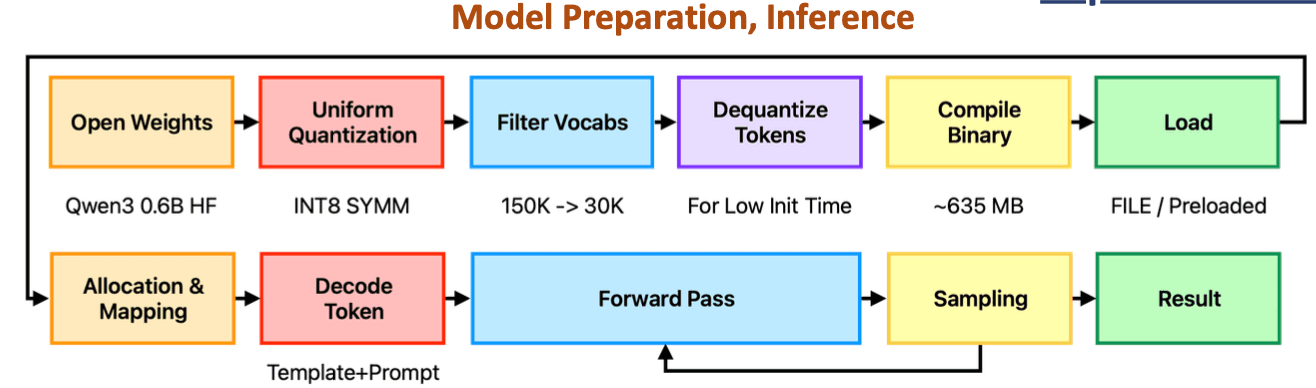
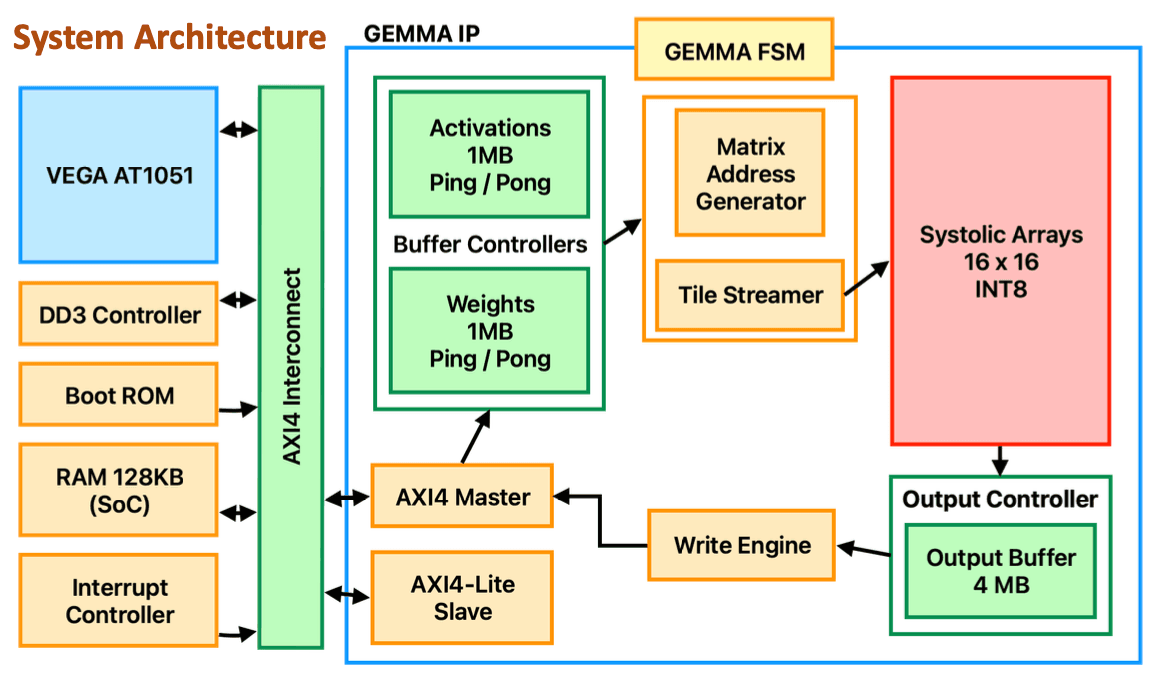
Designed a complete hardware-software co-design framework enabling Qwen3 SLM inference on the VEGA AT1051 RISC-V SoC, reducing latency from minutes to seconds through FPGA-accelerated GEMM offloading.
Built a full bare-metal runtime capable of executing the entire Qwen3 pipeline, including custom memory allocation, tiling schedule generation, AXI-based data movement, and CPU–FPGA synchronization for deterministic sequential inference.
Developed a lightweight systolic array accelerator featuring INT8 GEMM, 16×16 tiled architecture, double buffering, AXI4/AXI-Lite integration, and optimized DMA dataflow - delivering high-throughput GEMM execution on edge hardware.